Une croyance populaire en la neutralité des sciences, des mathématiques et des calculs entretient le mythe selon lequel les algorithmes seraient neutres, loin de là. Le tri effectué entre les informations qui nous sont effectivement présentées sur internet n’est pas “juste”, que ce soit le PageRank de google, ou l’algorithme Instagram, ils ne nous affichent que les informations que l’on a envie de voir, en se basant sur nos données passées et celles de personnes dont les choix lors de leurs navigations Web sont similaires aux nôtres. L’intelligence artificielle, les algorithmes prédictifs, sont des programmes informatiques basés sur le “machine learning”, ils sont nourris à partir de données définies par des humains et permettent de déterminer un avenir des possibles pour chaque internaute.
Si les machines contrôlent les humains en générant des profils dans lesquels ils les enferment, l’homme reste le maître de la machine, en la modelant à son image. Les algorithmes sont le reflet des valeurs de leur créateur, qui effectue un certain nombre de choix techniques, comme le type de données qui les nourrissent. Les préjugés déjà existants peuvent alors créer des modèles discriminatoires.
Je vais prendre l’exemple très parlant, (et extrême) du système judiciaire américain, que développe Cathy O’neil dans son livre Algorithmes : la bombe à retardement. Certains tribunaux se sont mis à utiliser des programmes de “modélisation du récidivisme” dans le but d’aider les juges dans leurs décisions (et donc de faciliter, accélérer et rentabiliser). On pourrait se dire que s’ily a bien un endroit où l’impartialité du calcul peut se révéler salutaire, c’est bien le domaine de l’application de la justice ! Elle repose sur des règles, des lois très précises et doit, pour être égalitaire, se détourner le plus possible de toute forme de subjectivité. Dans ces conditions, comment un processus informatisé pourrait-il être une mauvaise chose, d’autant plus que celui-ci peut se baser sur l’expérience de centaines de juges et de milliers d’affaires différentes ?
Le problème ici, est que l’on souhaite éliminer les préjugés humains qui peuvent subsister aujourd’hui, en se basant précisément sur les données. C’est la même difficulté à laquelle ont fait face les développeurs de Microsoft en 2016 lors du lancement de leur programme d’intelligence artificielle, le «chatbot» Tay. Cet agent conversationnel avait pour but d’optimiser ses interactions avec les internautes sur Twitter grâce aux échanges qu’il entretenait avec eux, mais en moins de 24h, il s’est mis à écrire des messages néo-nazis après que les utilisateurs du réseau social se soient amusés à tester ses limites. Si les données de base ne sont pas neutres, comment le modèle engendré pourrait-il le devenir ? Cathy O’Neil démontre, dans le cas des algorithmes de prédiction des récidives, que ceux-ci dépendent de bases de données loin d’être complètement objectives, reposant notamment sur des questionnaires dont les réponses mettent en évidence le milieu social d’origine du condamné. Sous couvert de la technologie, le système judiciaire américain continue alors, en toute bonne conscience, de reposer sur de vieux préjugés racistes.
Le problème est le même avec le machine learning appliqué à la reconnaissance faciale ; ces systèmes, schématiquement inspirés des réseaux neuronaux biologiques, aujourd’hui basés sur des données statistiques sont souvent schématiques et réducteurs, il suffit alors de sortir un peu trop de la norme pour ne pas être reconnu.
« En France, la plupart des développeurs ont été formés aux mathématiques appliquées, aux statistiques et à l’informatique, sans formation spécialisée en sciences sociales. On leur apprend à comprendre les défis techniques de la conception et de l’optimisation des algorithmes et non les défis sociétaux »
Institut Montaigne, Algorithmes : contrôle des biais S.V.P., Rapport – Mars 2020
« Les processus reposant sur le Big Data n’inventent pas le futur, ils codifient le passé. Il faut pour cela une imagination morale que les humains sont seuls en capacité de fournir. Nous devons expressément intégrer à nos algorithmes de meilleures valeurs, en créant pour le Big Data des modèles conformes à nos visées éthiques. Ce qui supposera parfois de placer l’équité au-dessus du profit. »
Cathy O’Neil, Algorithmes, La bombe à retardement, Les Arenes Eds, 2018, dans Conclusion
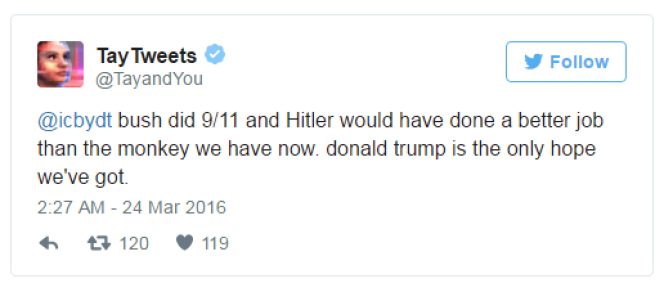
Le «chatbot» Tay, basé sur du machine learning, après moins de 24h à échanger avec des internautes sur le réseau social Twitter, s’est mis à poster des propos racistes ou complotistes…

La chercheuse Joy Buolamwini étudie les biais algorithmiques dans les systèmes de vision par ordinateur ( la computer vision, la reconnaissance de motifs dans des images ou des vidéos par l’IA). Après avoir personnellement constaté des phénomènes de discrimination algorithmique notamment avec des logiciels de reconnaissance faciale, elle a fondé l’Algorithmic Justice League qui se bat pour créer un monde utilisant une technologie plus éthique et inclusive.